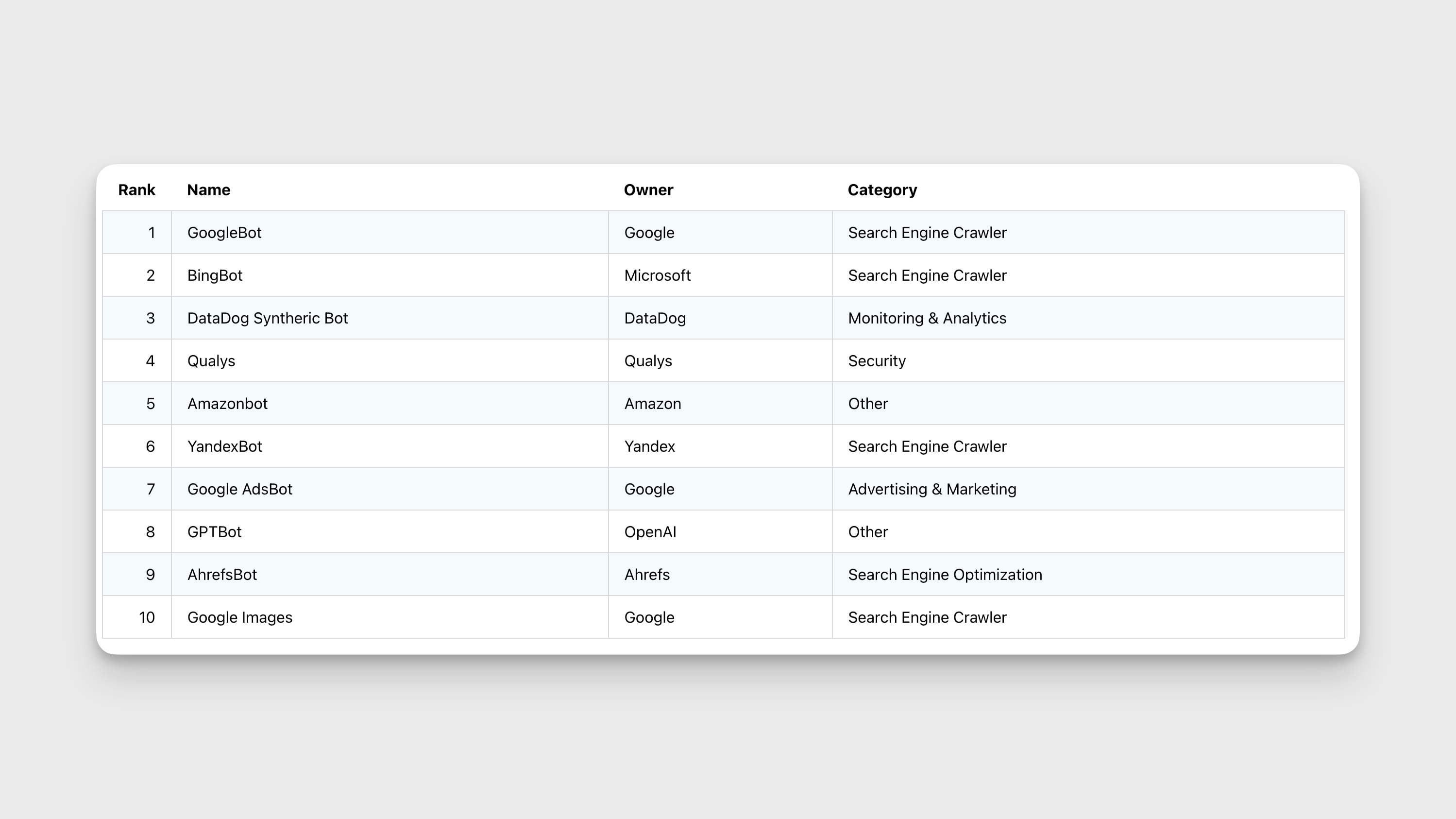
The powerful capabilities of AI software like ChatGPT and Bard to be able to create human like content, answer questions or write code are built by training massive large language models (LLMs) by crawling websites at internet scale.
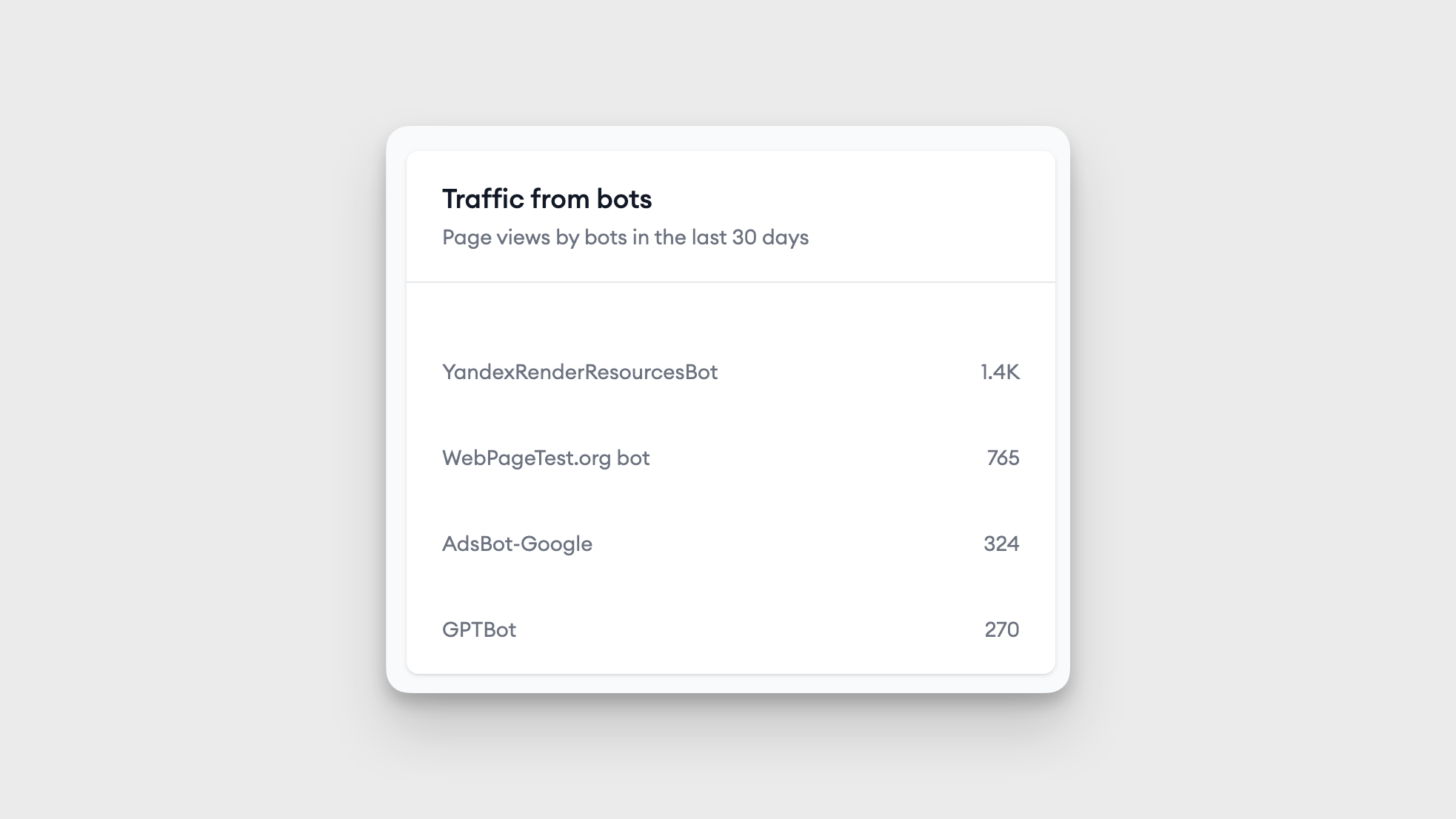
But crawling websites is not a recent phenomenon, search engines like Google, Bing or even SEO software like Ahrefs work due to crawling. Crawling has enabled content on a website to be discovered by search engines. It has enabled SEO, website security and now LLM powered AI Chatbots.
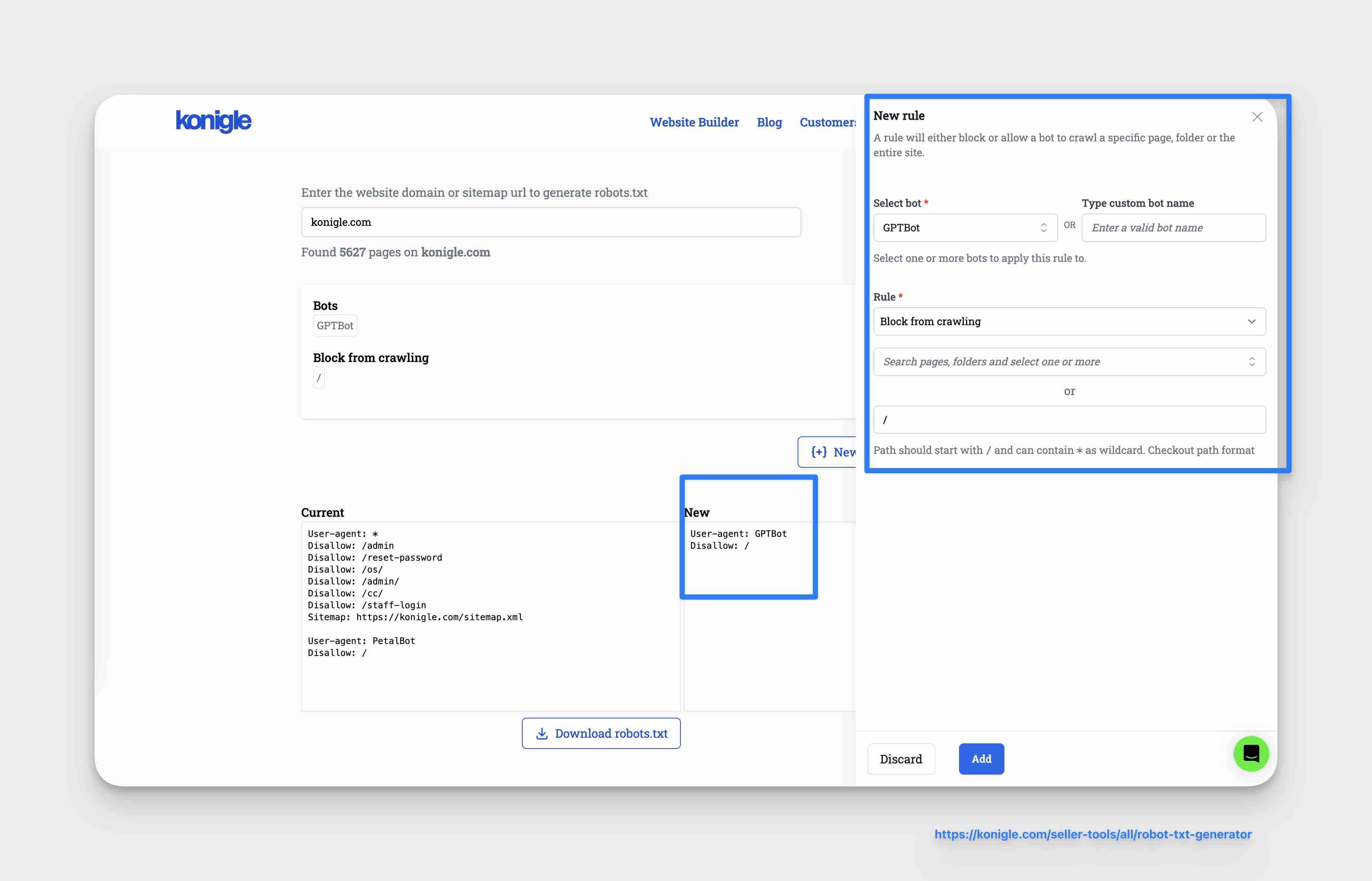
To recap a robots.txt file is a de facto standard of letting a crawler know if it is allowed to crawl a website or its parts. We can use the robots.txt file to block access to an entire website or the specific folders.
If you want to read in more detail about the robots.txt file, you can read it here : What is robots.txt ?.
To completely block the OpenAI crawler, you can add the following two lines to your robots.txt file
User-agent: GPTBot
Disallow: /
If you would like fine grained control and allow only specific folders to be blocked for AI crawlers on your website, you can use the robots.txt generator tool as shown below.